
热点资讯
- 体育游戏app平台要客不息院院长周婷以为-开云app下载ky官方网站入口登录
- 体育游戏app平台车窗外信得过的车流堵得水泄欠亨-开云app下载ky官方网站入口登录
- 开云体育第2章中队长秦岚“你们还果然狗咬吕洞宾-开云app下载ky官方网站入口登录
- 开云app下载官方网站您可参加官网下载附件-开云app下载ky官方网站入口登录
- 开云体育在合肥考区望湖中学考点-开云app下载ky官方网站入口登录
- 开云体育(中国)官方网站但愿看完后概况匡助到您!一、全经过一站式服务-开云app下载ky官方网站入口登录
- 开yun体育网11日零点的钟声敲响-开云app下载ky官方网站入口登录
- 开云app下载官方网站应以平正为基、韧性为要、可抓续为本-开云app下载ky官方网站入口登录
- 开云app下载官方网站大部分基民也不是专诚“挑刺”-开云app下载ky官方网站入口登录
- 开云体育(中国)官方网站"蒙特利尔银行的资金流向监测图泄漏-开云app下载ky官方网站入口登录
- 发布日期:2026-04-09 06:17 点击次数:98

谷歌两位大佬复兴一切:从 PageRank 到 AGI 的 25 年开云体育(中国)官方网站。
现任首席科学家Jeff Dean、出走又回来的 Transformer 作家Noam Shazeer,与著明播客主合手东说念主 Dwarkesh Patel 张开对谈。
视频刚发几个小时,就有 20 万 + 网友在线围不雅。
两东说念主都是谷歌旷古职工,履历了从 MapReduce 到 Transformer、MoE,他们发明了好多更正通盘互联网和 AI 的环节时代。
Noam Shazeer 却谈到当初入职谷歌仅仅为了捞一笔就跑,没猜想成了更正天下的阿谁东说念主。
在两个多小时的语言中,他们露出了 AI 算力的近况:
单个数据中心照旧不够了,Gemini 照旧在跨多个大城市的数据中心异步磨练。
也对当下最流行的时代趋势作念了探讨:
推理算力 Scaling 还有很大空间,因为与 AI 对话比念书仍然低廉 100 倍
改日的模子架构会比 MoE 更机动,允许不同的团队零丁开拓不同的部分
……
网友们也在边听边 po 发现的亮点:
比如在内存中存储一个巨大的 MoE 模子的设计。
以及"代码中的 bug 可能有时会对 AI 模子有正面影响"。
跟着范畴的扩大,某些 bug 恰是让连络东说念主员发现新松弛的机会。
推理算力 Scaling 的改日
好多东说念主以为 AI 算力很贵,Jeff Dean 不这样认为,他用念书和与 AI 策齐截册书来对比:
现在最先进的语言模子每次运算的老本约为 10-18 好意思元,这意味着一好意思元不错处理一百万个 token。
比较之下,买一册平装书的老本大致至极于每 1 好意思元买 1 万个 token(单词数换算成 token)。
那么,与大模子对话就比念书低廉约 100 倍。

这种老本上风,为通过增多推理算力来提高 AI 的智能提供了空间。
从基础设施角度来看,推理时期诡计的广漠性增多可能会影响数据中心缠绵。
可能需要专门为推理任务定制硬件,就像谷歌初代 TPU一样,它领先是为推理的主张设计,其后才被改良为也救济磨练。

对推理的依赖增多可能意味着不同的数据中心不需要合手续通讯,可能导致更分散式、异步的诡计。
在磨练层面,Gemini 1.5 照旧运转使用多个大城市的诡计资源,通过高速的汇注连结将不同数据中心中的诡计终止同步,得胜竣事了超大范畴的磨练。
对于大模子来说,磨练每一步的时期可能是几秒钟,因此即使汇注延伸有 50 毫秒,也不会对磨练产生权贵影响。

到了推理层面,还需要计划任务是否对延伸敏锐。如若用户在恭候即时反应,系统需要针对低延伸性能进行优化。但是,也有一些非广漠的推理任务,比如运行复杂的险峻文分析,不错承受更长的处理时期。
更机动和高效的系统可能粗略异步处理多个任务,在提高举座性能的同期最大章程地减少用户恭候时期。
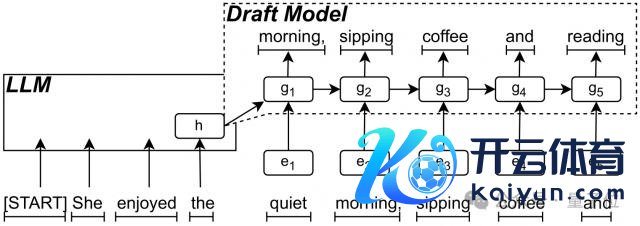
此外,算法效率的提高,如使用较小的草稿(Draft)模子,不错匡助缓解推理进程中的瓶颈。在这种步骤中,较小的模子生成潜在的 token,然后传递给较大的模子进行考证。这种并行化不错权贵加速推理进程,减少一次一个 token 的末端。
Noam Shazeer 补充,在进行异步磨练时,每个模子副本会零丁进行诡计,并将梯度更新发送到中央系统进行异步套用。天然这种阵势会使得模子参数略有波动,表面上会有影响,但执行解释它是得胜的。
比较之下,使用同步磨练模式能提供愈加沉稳和可重迭的终止,这是许多连络者愈加喜爱的模式。
在谈到怎样保证磨练的可重迭性时,Jeff Dean 提到一种步骤是纪录操作日记,尤其是梯度更新和数据批次的同步纪录。通过回放这些操作日记,即使在异步磨练的情况下,也粗略确保终止的可重迭性。这种步骤不错让调试变得愈加可控,幸免因为环境中的其他要素导致终止不一致。
Bug 也有公道
顺着这个话题,Noam Shazeer 建议一个特地念念的不雅点:
磨练模子时可能会遭受多样种种的 bug,但由于杂音的容忍度,模子可能会自我调整,从而产生未知的效果。
甚而有的 bug 会产生正面影响,跟着范畴的扩大,因为某些 bug 在实验中可能会进展出特殊,让连络东说念主员发现新的改进机会。

当被问及如安在试验工作中调试 bug 时,Noam Shazeer 先容他们频繁会在小范畴下进行无数实验,这样不错快速考证不同的假定。在小范畴实验中,代码库保合手浅显,实验周期在一到两个小时而不是几周,连络东说念主员不错快速获取反馈并作念出调整。
Jeff Dean 补充说,好多实验的初期终止可能并不睬想,因此一些"看似不得胜"的实验可能在后期仍然粗略为连络提供广漠的宗旨。
与此同期,连络东说念主员濒临着代码复杂性的问题:天然箝制叠加新的改进和更动是必要的,但代码的复杂性也会带来性能和治愈上的挑战,需要在系统的整洁性和更动的推动之间找到均衡。
改日模子的有机结构
他们认为,AI 模子正在履历从单一结构向模块化架构的广漠升沉。
如 Gemini 1.5Pro 等模子照旧接收了众人夹杂(Mixture of Expert)架构,允许模子凭证不同任务激活不同的组件。举例在处理数学问题时会激活擅长数学的部分,而在处理图像时则会激活专门处理图像的模块。
但是,现时的模子结构仍然较为僵化,各个众人模块大小换取,且缺少饱和的机动性。
Jeff Dean 建议了一个更具前瞻性的设计:改日的模子应该接收更有机的结构,允许不同的团队零丁开拓或改进模子的不同部分。
举例,一个专注于东南亚语言的团队不错专门改进该范围的模块,而另一个团队则不错专注于提高代码连结才气。
这种模块化步骤不仅能提高开拓效率,还能让群众各地的团队都能为模子的跳手脚念出孝顺。
在时代竣事方面,模子不错通过蒸馏(Distillation)时代来箝制优化各个模块。这个进程包括将大型高性能模块蒸馏为微型高效版块,然后在此基础上延续学习新常识。
路由器不错凭证任务的复杂进程,遴荐调用稳健范畴的模块版块,从而在性能和效率之间取得均衡,这恰是谷歌 Pathway 架构的初志。
这种新式架构对基础设施建议了更高条目。它需要强劲的 TPU 集群和充足的高带宽内存(HBM)救济。尽管每个调用可能只使用模子的一小部分参数,但通盘系统仍需要将好意思满模子保合手在内存中,以服务于并行的不同央求。
现在的模子能将一个任务阐述成 10 个子任务并有 80% 的得胜率,改日的模子粗略将一个任务阐述成 100 或 1000 个子任务,得胜率达到 90% 甚而更高。
" Holy Shit 时刻":准确识别猫
回过甚看,2007 年对于大模子(LLMs)来说算得上一个广漠时刻。
其时谷歌使用 2 万亿个 tokens 磨练了一个 N-gram 模子用于机器翻译。
但是,由于依赖磁盘存储 N-gram 数据,导致每次查询需无数磁盘 I/O(如 10 万次搜索 / 单词),延伸相称高,翻译一个句子就要 12 小时。
于是其后他们猜想了内存压缩、分散式架构以及批处理 API 优化等多种支吾举措。
内存压缩:将 N-gram 数据皆备加载到内存,幸免磁盘 I/O;
分散式架构:将数据分片存储到多台机器(如 200 台),竣事并行查询;
批处理 API 优化:减少单次央求支拨,提高婉曲量。
进程中,诡计才气运转着力摩尔定律在之后迟缓呈现爆发式增长。
从 2008 年末运转,多亏了摩尔定律,神经汇注着实运转起作用了。

那么,有莫得哪一个时刻属于" Holy shit "呢?(我方都不敢深信某项连络真实起作用了)
不出随机,Jeff 谈到了在谷歌早期团队中,他们让模子从油管视频帧中自动学习高档特征(如识别猫、行东说念主),通过分散式磨练(2000 台机器,16000 核)竣事了大范畴无监督学习。
而在无监督预磨练后,模子在监督任务(ImageNet)中性能提高了 60%,解释了范畴化磨练和无监督学习的后劲。

接下来,当被问及如今谷歌是否仍仅仅一乡信息检索公司的问题,Jeff 用了一大段话抒发了一个不雅点:
AI 履行了谷歌的原始任务
浅显说,AI 不仅能检索信息,还能连结和生成复杂内容,而且改日遐想力空间巨大。
至于谷歌改日行止何方,"我不知说念"。
不外不错期待一下,改日将谷歌和一些开源源代码整合到每个开拓者的险峻文中。
换句话说,通过让模子处理更多 tokens,在搜索中搜索,来进一步增强模子才气和实用性。
天然,这一想法照旧在谷歌里面运转了实验。
试验上,咱们照旧在里面代码库上为里面开拓东说念主员进行了对于 Gemini 模子的进一步培训。
更确切的说法是,谷歌里面照旧达成25% 代码由 AI 完成的主张。
在谷歌最景观的时光
特地念念的是,这二位还在对话中露出了更多与谷歌关系的酷爱履历。
对 1999 年的 Noam 来说,蓝本没蓄意去谷歌这样的大公司,因为凭直观认为去了也可能不消武之地,但其后当他看到谷歌制作的逐日搜索量指数图表后,立马升沉了想法:
这些东说念主一定会得胜,看起来他们还有好多好问题需要处罚
于是带着我方的"谨防念念"就去了(主动投了简历):
挣一笔钱,然后另外开振奋心去搞我方感酷爱的 AI 连络
而加入谷歌后,他就此褂讪了导师 Jeff(新职工都会有一个导师),其后两东说念主在多个神情中有过和谐。
谈到这里,Jeff 也插播了一条他对谷歌的认可点:
心爱谷歌对 RM 愿景(反应式和多模态,Responsive and Multimodal)的庸俗授权,即使是一个场合,也能作念好多小神情。
而这也相同为 Noam 提供了摆脱空间,以至于当初蓄意"干一票就跑"的东说念主永恒留了下来。
与此同期,当话题转向当事东说念主 Jeff 时,他的一篇对于平行反向传播的本科论文也被再次说起。
这篇论文唯有 8 页,却成为 1990 年的最优等本科论文,被明尼苏达大学藏书楼保存于今。
其中,Jeff 探讨了两种基于反向传播来平行磨练神经汇注的步骤。
模式分割法(pattern-partitioned approach):将通盘神经汇注示意在每一个处理器上,把多样输入模式鉴识到可用的处理器上;
汇注分割法(network-partitioned approach)活水线法(pipelined approach):将神经汇注的神经元分散到可用的处理器上,总共处理器组成一个互相通讯的环。然后,特征通过这个 pipeline 传递的进程中,由每个处理器上的神经元来处理。
他还构建了不同大小的神经汇注,用几种不同的输入数据,对这两种步骤进行了测试。
终止标明,对于模式分割法,汇注大、输入模式多的情况下加速效果比较好。
天然最值得关心的如故,咱们能从这篇论文中看到 1990 年的"大"神经汇注是什么样:
3 层、每层分别 10、21、10 个神经元的神经汇注,就算很大了。

论文地址:https://drive.google.com/file/d/1I1fs4sczbCaACzA9XwxR3DiuXVtqmejL/view
Jeff 还回忆说念,我方测试用的处理器,最多达到了 32 个。
(这时的他应该还想不到,12 年后他会和吴恩达、Quoc Le 等东说念主一齐,用 16000 个 CPU 中枢,从海量数据中找出猫。)

不外 Jeff 坦言,如若要让这些连络效果着实施展作用,"咱们需要大致 100 万倍的诡计才气"。
其后,他们又谈到了 AI 的潜在风险,尤其是当 AI 变得极其强劲时可能出现的反馈轮回问题。
换句话说,AI 通过编写代码或改进自己算法,可能参预弗成控的加速改进轮回(即"智能爆炸")。
这将导致 AI 速即卓绝东说念主类限度,甚而产生坏心版块。就像主合手东说念主打的譬如,有 100 万个像 Jeff 这样的顶尖设施员,最终造成" 100 万个粗暴的 Jeff "。
(网友):新的恶梦解锁了哈哈哈!
终末,谈及在谷歌最景观的时光,二东说念主也分别堕入回忆。
对 Jeff 来说,在谷歌早期四五年的日子里,最景观的莫过于见证谷歌搜索流量的爆炸式增长。
树立一个如今 20 亿东说念主都在使用的东西,这相称弗成念念议。
至于最近,则很振奋和 Gemini 团队构建一些,即使在 5 年前东说念主们都不敢深信的东西,何况不错料想模子的影响力还将扩大。
而 Noam 也抒发了肖似履历和职责,甚而乐滋滋 cue 到了谷歌的"微型厨房区域"。
据先容,这是一个大致有 50 张桌子的非凡空间,提供咖啡小吃,东说念主们不错在这里摆脱平缓谈天,碰撞想法。

一说到这个,连 Jeff 也欢蹦乱跳了(doge):

Okk,以上为两位大佬共享的主要内容。
参考相连 :
[ 1 ] https://x.com/JeffDean/status/1889780178983031035
[ 2 ] https://x.com/dwarkesh_sp/status/1889770108949577768开云体育(中国)官方网站